Extending Pandas
Dr. Bryan Patrick Wood
December 21, 2021
Filed under “DS/AI/ML”
Open for extension, but closed for modification is a solid1 recommendation indeed. I love software that supports extension. I've had a particular fascination with extension mechanisms in software throughout my career. I've also been lucky enough to work on several including
- Writing plugins for a homegrown C++ data orchestration framework while at Raytheon Solipsys This is before there were a lot of quality open-source data orchestration solutions available (e.g., Airflow, Nifi, etc.).
- Writing my own homegrown data orchestration framework from scratch in Java while at Focused Support
- This was pure joy: marrying my love for C++, Boost, and Python! Writing a framework to support Python scriptable components in a C++ application while at Stellar Science
- Writing a report generation framework in Python supporting pluggable section content using the pluggy More on this in the future.and reportlab Python packages at my current position with Leidos
A predilection, mayhaps. Like a moth to the flame, when I discovered one of my most frequently used Python packages supported extension mechanisms I was compelled to look into it.
Who is this for?
Although practicality beats purity2.
Maybe you're not a software architecture wonk aficionado. That's fair: I'd speculate that's the
exception rather than the rule for folks using pandas3. This is not a deep dive into how the extension mechanisms are
implemented. Interesting in their own right but out of the intended scope.
The official documentation for extending pandas4 mentions four ways
in which pandas can be extended
- Custom accessors
- Custom data types
- Subclassing existing pandas data structures
- Third-party plotting backends
The focus here will be almost exclusively on #1: custom accessors. This is the one case I had a use for and think most
pandas users could benefit from knowing about.
What are some reasons to continuing reading? Maybe you've noticed a few verbose pandas
statements that seem to recur often in your notebooks or scripts. Or maybe you're a teammate noticing the same mistakes
or deviations from best practices during code review. Or maybe you're just a bit perverse and want to bend pandas to
your will. If this is you good reader, read on: what follows is practical information that can be applied to these ends.
What is an Accessor?
If you've used pandas for any amount of time you will already be familiar with them. pandas ships with a few builtin
accessors on the Series and DataFrame classes
Series.cat,Series.dt,Series.plot,Series.sparse, andSeries.strDataFrame.plotandDataFrame.sparse
I use Series.str5 all the time for manipulating string type columns in DataFrames. It provides
vectorized string methods mirroring the Python standard library ones intelligently skipping over NAs. Series.plot
and DataFrame.plot are another two that I use frequently whereas I have never had the occasion to use Series.sparse
or DataFrame.sparse. The type of data you work with most often will dictate which will be most familiar so YMMV.
Your Mileage May Vary
(YMMV)
Example usage is straight forward
print(pd.Series(['bar', 'baz']).str.upper().str.replace('B', 'Z'))
0 zAR
1 zAZ
dtype: object
Boilerplate
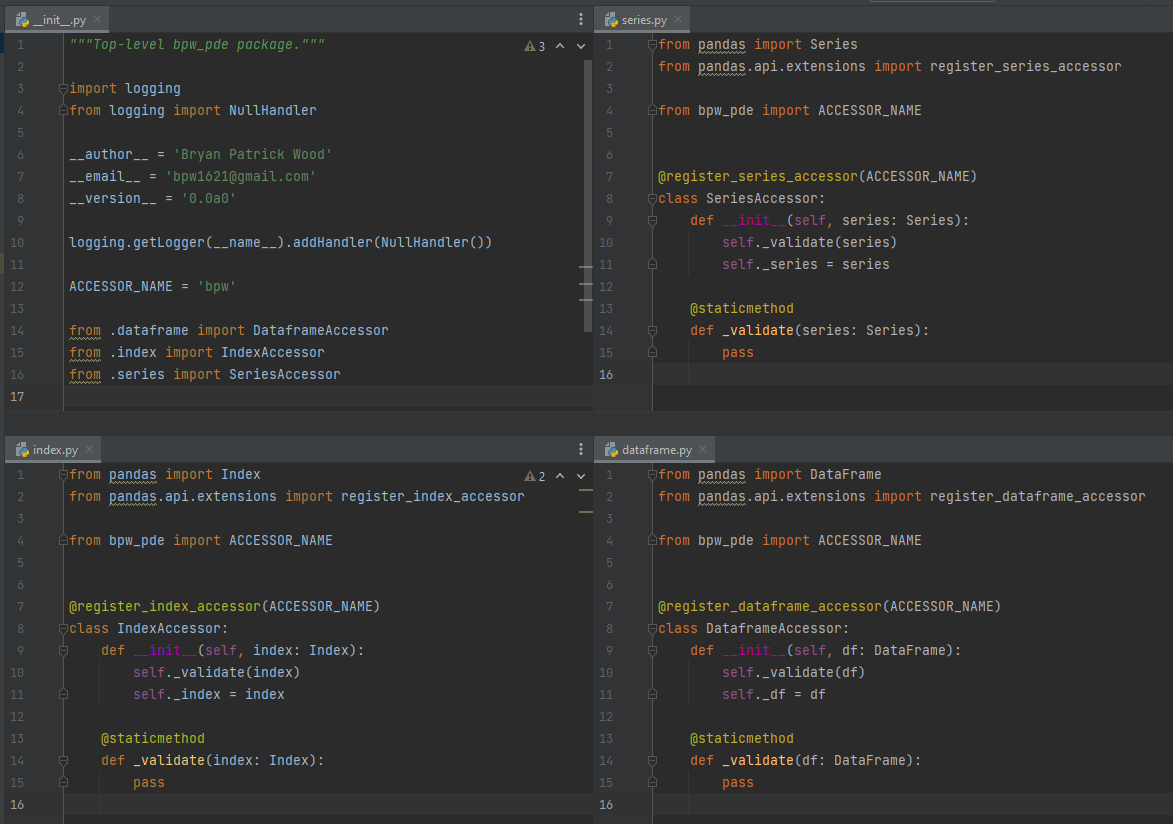
Pandas supports registering custom accessors for its Index, Series, and DataFrame classes via decorators in the
pandas.api.extensions module. These decorators expect a class which is passed the respective object as the only
non-self argument to its __init__ method.
Here is the src directory structure
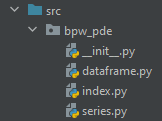 The minimal boilerplate necessary for creating a pandas accessor for each supported
class is shown in the figure below. If you only intend to write a
The minimal boilerplate necessary for creating a pandas accessor for each supported
class is shown in the figure below. If you only intend to write a DataFrame accessor the series.py and index.py
modules can be removed. The package naming and the accessor are both personalized with my initials. Since this
effectively creates a namespace within the respectively classes it's first come, first served: sorry Bernard Piotr
Wojciechowski6.
Viz., the pandas documentation for a geo DataFrame accessor that requires lat and lon
columns.4
Including _validate methods is generally a good idea especially for special purpose accessors that only make sense to
use on objects that meet enforceable preconditions. Since this is meant to be more of a grab bag of personal
conveniences, validation will get pushed down to the individual accessor methods as appropriate obviating the need for
top level validation.
With that in place we can verify everything is working
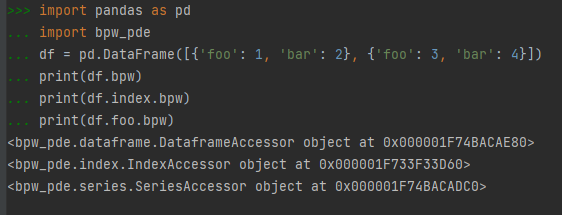
The custom accessors do not have any useful methods or properties yet; however, at this point it's off to the races.
What to Add?
That's completely up to you: you now have your own pandas extension module. Pretty sweet! A good place to start is
looking through your projects, scripts, notebooks, etc., that use pandas for patterns and repeated statements. Easy
targets are
- Any functions that show up in frequently in
pandasHoF calls (e.g.,apply,map,applymap,aggregate,transform, etc.)Higher-order Function (HoF). pandassetup code can be pushed into the module__init__.py- Proxies and aliases
Still stumped? I'll share some snippets for what I added to mine after creating the boilerplate to assist in your ideation process. I've elided details in the interest of brevity. For those details, the full code can be found on GitHub and the package can be installed from PyPI.
Subject Matter Expert (SME).
In my current position, the folks I'm working with are more likely to be SMEs in an area outside my own vice data
scientists. As a result, I'm passed all sorts of unhygienic data and have amassed a variety of cleaning routines.
Adding a common.py to collect these functions decoupled from their embedding in the accessors
PUNCTUATION_TO_SPACE_TRANSLATOR = str.maketrans(string.punctuation, ' ' * len(string.punctuation))
DEFAULT_UNICODE_NORMALIZATION_FORM = 'NFKC'
def clean_name(name: str):
return '_'.join(name.lower().translate(PUNCTUATION_TO_SPACE_TRANSLATOR).split())
def unicode_normalize(text: str, form: str = DEFAULT_UNICODE_NORMALIZATION_FORM):
return unicodedata.normalize(form, text)
Referencing it in series.py
@register_series_accessor(ACCESSOR_NAME)
class SeriesAccessor:
@property
def clean_name(self):
series = self._series.copy()
series.name = clean_name(series.name)
return series
def normalize(self, form: str = DEFAULT_UNICODE_NORMALIZATION_FORM):
series = self._series.copy()
return series.apply(functools.partial(unicode_normalize, form=form))
And in dataframe.py
@register_dataframe_accessor(ACCESSOR_NAME)
class DataframeAccessor:
@property
def clean_names(self):
df = self._df.copy()
df.columns = [clean_name(column) for column in df.columns]
return df
We get our first set of useful custom accessor capabilities. clean_name and clean_names
While researching I found pyjanitor7 which has a more robust name cleaning
capability8. A ton of other useful stuff there: strongly encourage taking a look.
should be pretty self-explanatory: lowercase, replace all special characters with
space, tokenize, and concatenate the tokens with underscores; normalize does Unicode
normalization9.
Doing an expensive operation on a big DataFrame or Series? You're going to want an estimate of when it's likely to
An example of #2 above. There are certainly other (better?) ways to do this in interactive environments like ipython and jupyter startup scripts.
be done. I've settled on tqdm10 for monitoring task progress in Python. It also conveniently has builtin support
for pandas. However, this support needs to be initialized which can be easily dropped into the package __init__.py
as follows
from tqdm.autonotebook import tqdm
tqdm.pandas()
sidetable, itself a pandas custom accessor, provides a few DataFrame summarizations:
specifically, I use its freq method ... frequently. missingno provides visualizations for understanding the missing
information in a DataFrame.
Two packages I use frequently when analyzing data with pandas are the sidetable11 and
missingno12 packages.
I usually want them around when I am using pandas. Baking them into the custom accessor is an easy way to do that as
well as provide some usage convenience.
Here's the relevant code
class _MissignoAdapter:
def __init__(self, df: DataFrame):
self._df = df
def matrix(self, **kwargs):
return missingno.matrix(self._df, **kwargs)
def bar(self, **kwargs):
return missingno.bar(self._df, **kwargs)
def heatmap(self, **kwargs):
return missingno.heatmap(self._df, **kwargs)
def dendrogram(self, **kwargs):
return missingno.dendrogram(self._df, **kwargs)
@register_dataframe_accessor(ACCESSOR_NAME)
class DataframeAccessor:
@property
def stb(self):
return self._df.stb
def freq(self, *args, **kwargs):
return self._df.stb.freq(*args, **kwargs)
@property
def msno(self):
return _MissignoAdapter(self._df)
In the case of sidetable, this makes sure it is available after an import bpw_pde, provides an alias in the custom
accessor to it, and pulls out the freq method to the top-level of the custom accessor. In the case of missingo, its
interface needs adapting to work as a top-level msno property
All problems in computer science can be solved by another level of indirection, except for the
problem of too many layers of indirection.13
on the custom accessor which is easily handled by
introducing a level of indirection through the adapter class.
Usage
The package __init__.py imports all the individual accessor classes so registration of the custom accessors
happens on package import, i.e., import bpw_pde. Following that you can use the custom accessor just like the builtin
ones, e.g.,
import pandas as pd
import matplotlib.pyplot as plt
import bpw_pde
df = pd.DataFrame(...)
df = df.bpw.clean_names
df.text = df.text.bpw.normalize()
print(df.bpw.freq(['foo']))
df.bpw.msno.matrix()
plt.show()
For additional usage, the package has tests which is always one of the first places to look when trying to figure out how exactly to use some code.
What Else?
Plenty as you might imagine. As mentioned above there are four different ways to extend pandas. I've only touched on
one in any detail here. A few final thoughts across all extension mechanisms follow.
I'd strongly recommend checking out the pandas official documentation on the pandas ecosystem14.
Most of the examples mentioned in the rest of this section can be found there as well as a treasure trove of unmentioned
pandas goodies.
Custom accessors
Hopefully a well beaten horse at this point. I will site another blog post on this topic I came across and found interesting on this topic for the unsated reader.
I've already mentioned sidetable as a custom pandas accessor I use, and I've also created one, bpw_pde, you can
install and use in your next project if you find it useful. pandas_path3 is another I'd recommend
taking a look at as a huge proponent and user of Python's bultin pathlib functionality.
It would also be remiss not to mention an extension to pandas extension mechanism:

pandas_flavor15 16. The primary additional functionality you get with
pandas_flavor is the ability to register methods directly onto the underlying pandas type without an intermediate
accessor. Bad idea? I think it's probably safer to namespace your extensions vice effectively
monkeypatching pandas core
data structures; however, I can also see the counterargument in exploratory data analysis environments.
Context is everything.
pyjanitor, mentioned above, uses pandas_flavor's direct method registration vice the builtin pandas custom
Application Programming Interface (API).
accessor extension API.
Custom data types
This is absolutely another extension mechanism I can see having a need for in the future that I did not know about
before diving into this topic for the package and blog post. However, I didn't want to create a contrived one just
for the blog post because there are other good, useful open-source Python packages that do this. The documentation
e.g., cyberpandas17 for custom data types related to IP Addresses.
on this topic is pretty good and the ecosystem page has examples. I also recommend watching
this dated but still relevant talk by core developer Will Ayd on the topic.
Subclassing existing pandas data structures
This is a much more time-consuming endeavor you'll need a good reason to pursue. To some degree, with custom accessors,
this may be rarely needed in new code relegated mostly to the trash heap of legacy. Not a ton of good reasons come to
But, again, I can't think of a good reason why you'd need to do that either.
mind but if you ever needed to override a pandas data structure method that might be one. A good example here that
I've used extensively is geopandas18.
Third-party plotting backends
Very cool that this is supported but also incredibly niche. I can't imagine even most advanced users and developers of
pandas and related packages will ever need to use this. However, they may well benefit from it when a new plotting
package developer can take advantage of it.