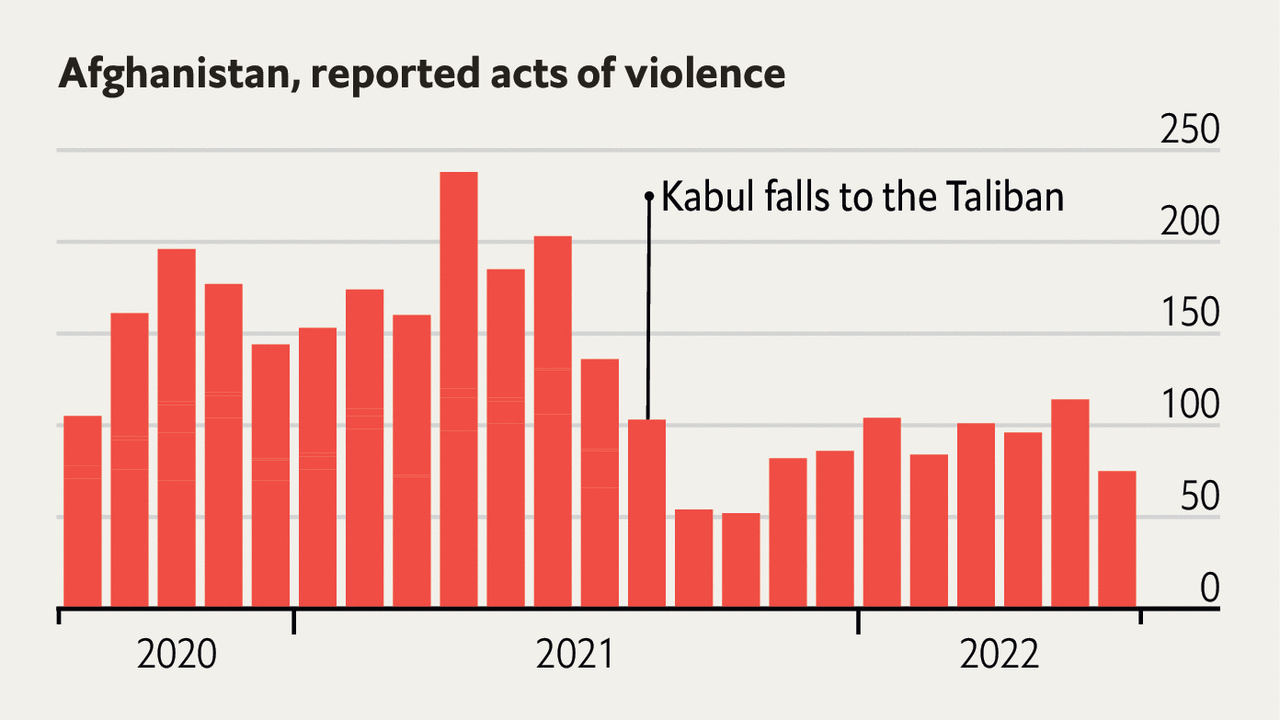Just looked. I have not published a new blog post all year so far: good work. I have been working on
a couple different projects I intend to write blogs on. None have gotten to where I feel like they are ready for
Still tinkering as usual. Fun stuff in the near future is coming.
the writing to begin though.
So if nothing is ready why am I writing a blog post? Well, turns out I spotted another pretty little butterfly to chase
and distract me from actually finishing the other projects I have in progress. In fairness, most of those other
projects are longer-term and more involved than what I'll be writing about today. Nothing groundbreaking. May be of
interest to folks trying to
E.g., a proficiency listed on a resume: in this case data visualization using Python.
hone their data science craft or looking for proof of competency.
Koans
I am no Zen Master.
Although I continue to enjoy listening to quite a bit of
Alan Watts on Audible.
My understanding is that a koan is an inscrutable parable intended to free the mind from rational constructs needed to
fully engage in
Happy to be educated if that's way off base.
many Zen Buddhist tradition's training rituals.
When the many are reduced to one, to what is the one reduced?
What is the colour of wind?
Yep, clear as mud.
In the context of programming, the term has been co-opted to mean something like a puzzle to be solved often in the
construct of TDD.
Test Driven Development (TDD).
This could be something like a sequence of tests presented to the student to create or modify a function or class so
that it passes those tests one after another.
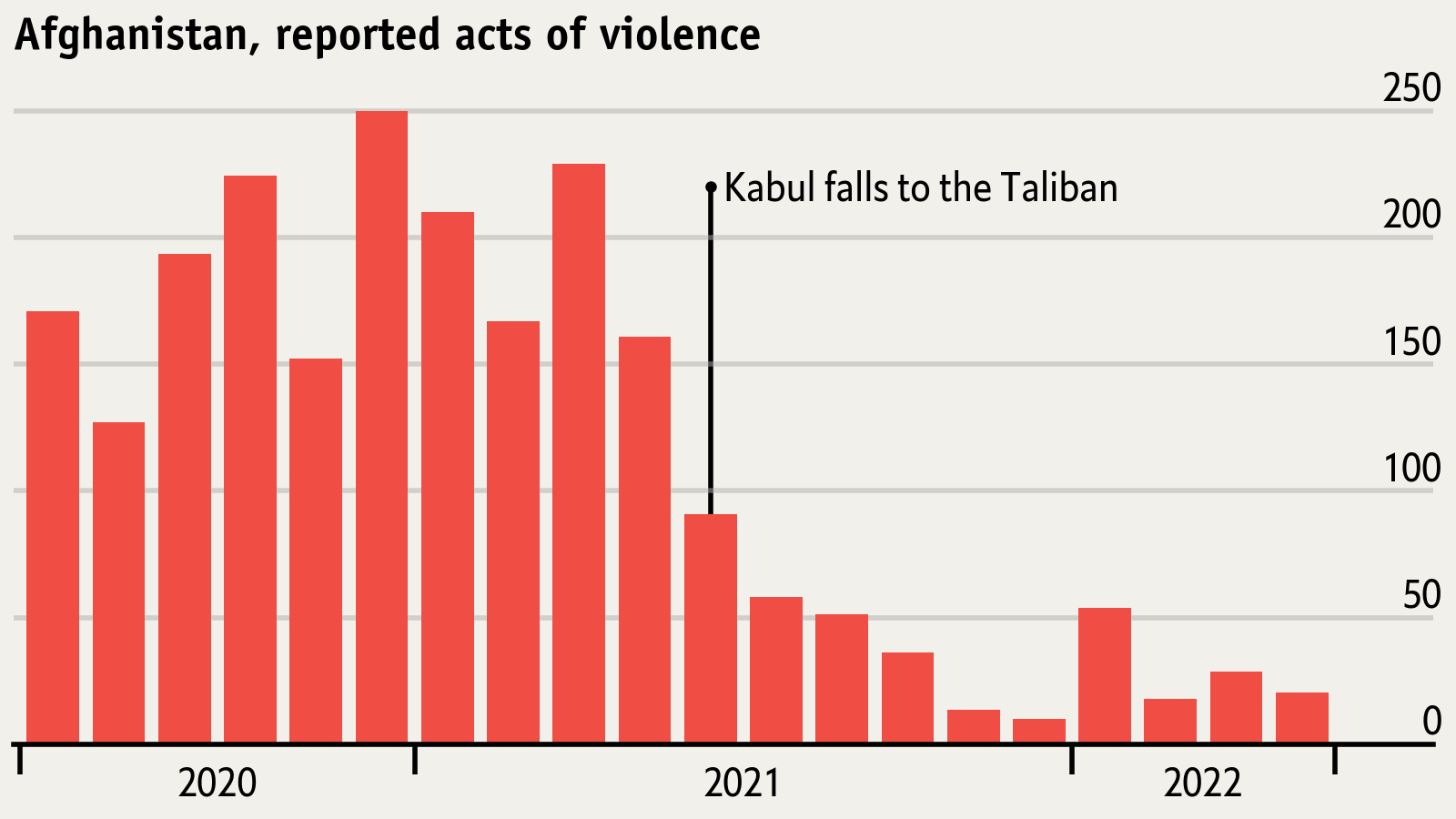
It's in this spirit that I created pyvizkoans. Specifically, I came across a
handsome chart published on the economist.com and wondered
The Economist's Graphic detail has a wealth of
inspiration to choose from. They also publish their design system2 which contains helpful details (e.g., fonts).
how difficult it would be to reproduce in Python. So I spun up Jupyterlab and went to work. Using matplotlib I got
pretty close, learned new tricks, and enjoyed the process.
I created a repository for this because I intend to make a habit of doing one such chart study every now and again.
More often at work the focus is quick insights and not publication level aesthetics so it is a good thing to practice.
Numero Uno
So what do you think?
The Original
The Reproduction
One thing that'll jump out is that no attempt to recreate the underlying data was made: the data was randomly generated
in the spirit of the story the chart was trying to tell. The exercise was focused on the look and feel, not the data.
There are a couple other issues I just gave up on trying to fix: additional details can be found in the
notebook3. Even with all that said, I was not going for pixel perfect reproduction.
Closing Thoughts
Fun little exercise. I'd encourage others to try something like this themselves the next time you come across a graphic
online with a distinctive or interesting aesthetic. Although I love the Economist's graph design aesthetic I'll probably
find a different source for the next one since the goal is not to get good at reproducing Economist content. Varying
the source most certainly will have more pedagogical value. If anyone reading this has other suggestions for particular
charts or sources for charts I'd love to hear it: please leave a comment.
Open for extension, but closed for modification is a solid1 recommendation indeed.
I love software that supports extension. I've had a particular fascination with extension mechanisms in software
throughout my career. I've also been lucky enough to work on several including
Writing plugins for a homegrown C++ data orchestration framework while at Raytheon SolipsysThis is before there were a lot of quality open-source data orchestration solutions available
(e.g., Airflow, Nifi, etc.).
Writing my own homegrown data orchestration framework from scratch in Java while at Focused Support
This was pure joy: marrying my love for C++, Boost, and Python!
Writing a framework to support Python scriptable components in a C++ application while at Stellar Science
Writing a report generation framework in Python supporting pluggable section content using the pluggyMore on this in the future.and reportlab Python packages at
my current position with Leidos
A predilection, mayhaps. Like a moth to the flame, when I discovered one of my most frequently used Python packages
supported extension mechanisms I was compelled to look into it.
Who is this for?
Although practicality beats purity2.
Maybe you're not a software architecture wonk aficionado. That's fair: I'd speculate that's the
exception rather than the rule for folks using pandas3. This is not a deep dive into how the extension mechanisms are
implemented. Interesting in their own right but out of the intended scope.
The official documentation for extending pandas4 mentions four ways
in which pandas can be extended
Custom accessors
Custom data types
Subclassing existing pandas data structures
Third-party plotting backends
The focus here will be almost exclusively on #1: custom accessors. This is the one case I had a use for and think most
pandas users could benefit from knowing about.
What are some reasons to continuing reading? Maybe you've noticed a few verbose pandas
statements that seem to recur often in your notebooks or scripts. Or maybe you're a teammate noticing the same mistakes
or deviations from best practices during code review. Or maybe you're just a bit perverse and want to bend pandas to
your will. If this is you good reader, read on: what follows is practical information that can be applied to these ends.
What is an Accessor?
If you've used pandas for any amount of time you will already be familiar with them. pandas ships with a few builtin
accessors on the Series and DataFrame classes
Series.cat, Series.dt, Series.plot, Series.sparse, and Series.str
DataFrame.plot and DataFrame.sparse
I use Series.str5 all the time for manipulating string type columns in DataFrames. It provides
vectorized string methods mirroring the Python standard library ones intelligently skipping over NAs. Series.plot
and DataFrame.plot are another two that I use frequently whereas I have never had the occasion to use Series.sparse
or DataFrame.sparse. The type of data you work with most often will dictate which will be most familiar so YMMV.
Your Mileage May Vary
(YMMV)
Pandas supports registering custom accessors for its Index, Series, and DataFrame classes via decorators in the
pandas.api.extensions module. These decorators expect a class which is passed the respective object as the only
non-self argument to its __init__ method.
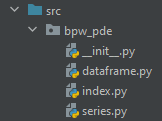
Here is the src directory structure
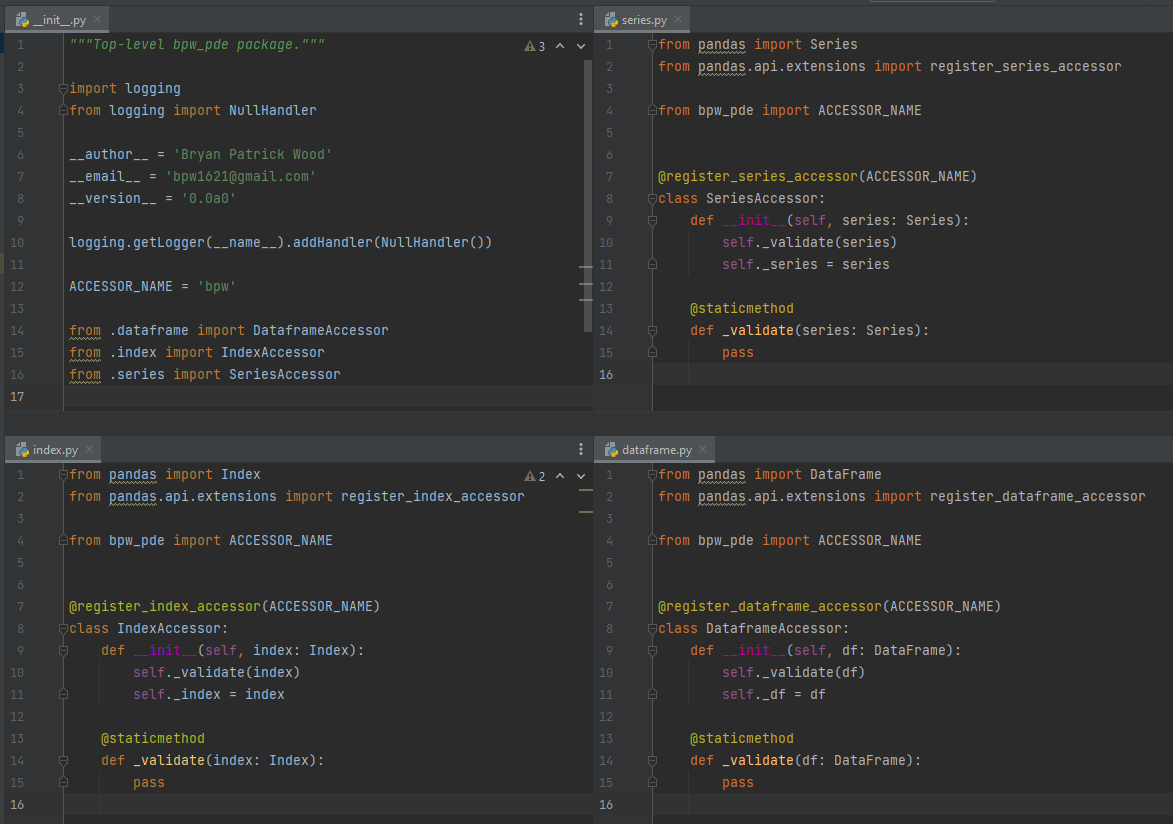
The minimal boilerplate necessary for creating a pandas accessor for each supported
class is shown in the figure below. If you only intend to write a DataFrame accessor the series.py and index.py
modules can be removed. The package naming and the accessor are both personalized with my initials. Since this
effectively creates a namespace within the respectively classes it's first come, first served: sorry Bernard Piotr
Wojciechowski6.
Viz., the pandas documentation for a geoDataFrame accessor that requires lat and lon
columns.4
Including _validate methods is generally a good idea especially for special purpose accessors that only make sense to
use on objects that meet enforceable preconditions. Since this is meant to be more of a grab bag of personal
conveniences, validation will get pushed down to the individual accessor methods as appropriate obviating the need for
top level validation.
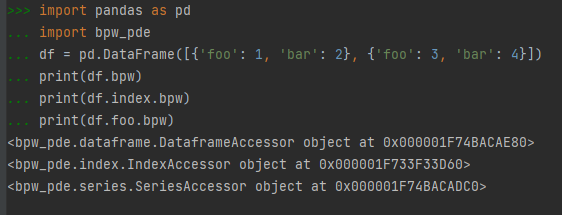
With that in place we can verify everything is working
The custom accessors do not have any useful methods or properties yet; however, at this point it's off to the races.
What to Add?
That's completely up to you: you now have your own pandas extension module. Pretty sweet! A good place to start is
looking through your projects, scripts, notebooks, etc., that use pandas for patterns and repeated statements. Easy
targets are
Any functions that show up in frequently in pandas HoF calls (e.g., apply, map, applymap, aggregate,
transform, etc.)Higher-order Function (HoF).
pandas setup code can be pushed into the module __init__.py
Proxies and aliases
Still stumped? I'll share some snippets for what I added to mine after creating the
boilerplate to assist in your ideation process. I've elided details in the interest of brevity. For those details, the
full code can be found on GitHub and the package can be installed from
PyPI.
Subject Matter Expert (SME).In my current position, the folks I'm working with are more likely to be SMEs in an area outside my own vice data
scientists. As a result, I'm passed all sorts of unhygienic data and have amassed a variety of cleaning routines.
Adding a common.py to collect these functions decoupled from their embedding in the accessors
We get our first set of useful custom accessor capabilities. clean_name and clean_namesWhile researching I found pyjanitor7 which has a more robust name cleaning
capability8. A ton of other useful stuff there: strongly encourage taking a look.
should be pretty self-explanatory: lowercase, replace all special characters with
space, tokenize, and concatenate the tokens with underscores; normalize does Unicode
normalization9.
Doing an expensive operation on a big DataFrame or Series? You're going to want an estimate of when it's likely to
An example of #2 above. There are certainly other (better?) ways to do this in interactive environments like ipython and jupyter startup scripts.
be done. I've settled on tqdm10 for monitoring task progress in Python. It also conveniently has builtin support
for pandas. However, this support needs to be initialized which can be easily dropped into the package __init__.py
as follows
fromtqdm.autonotebookimporttqdmtqdm.pandas()
sidetable, itself a pandas custom accessor, provides a few DataFrame summarizations:
specifically, I use its freq method ... frequently. missingno provides visualizations for understanding the missing
information in a DataFrame.Two packages I use frequently when analyzing data with pandas are the sidetable11 and
missingno12 packages.
I usually want them around when I am using pandas. Baking them into the custom accessor is an easy way to do that as
well as provide some usage convenience.
In the case of sidetable, this makes sure it is available after an import bpw_pde, provides an alias in the custom
accessor to it, and pulls out the freq method to the top-level of the custom accessor. In the case of missingo, its
interface needs adapting to work as a top-level msno property
All problems in computer science can be solved by another level of indirection, except for the
problem of too many layers of indirection.13
on the custom accessor which is easily handled by
introducing a level of indirection through the adapter class.
Usage
The package __init__.py imports all the individual accessor classes so registration of the custom accessors
happens on package import, i.e., import bpw_pde. Following that you can use the custom accessor just like the builtin
ones, e.g.,
For additional usage, the package has tests which is always one of the first places to look when trying to figure out
how exactly to use some code.
What Else?
Plenty as you might imagine. As mentioned above there are four different ways to extend pandas. I've only touched on
one in any detail here. A few final thoughts across all extension mechanisms follow.
I'd strongly recommend checking out the pandas official documentation on the pandas ecosystem14.
Most of the examples mentioned in the rest of this section can be found there as well as a treasure trove of unmentioned
pandas goodies.
I've already mentionedsidetable as a custom pandas accessor I use, and I've also created one, bpw_pde, you can
install and use in your next project if you find it useful. pandas_path3 is another I'd recommend
taking a look at as a huge proponent and user of Python's bultin pathlib functionality.
It would also be remiss not to mention an extension to pandas extension mechanism:
pandas_flavor1516. The primary additional functionality you get with
pandas_flavor is the ability to register methods directly onto the underlying pandas type without an intermediate
accessor. Bad idea? I think it's probably safer to namespace your extensions vice effectively
monkeypatchingpandas core
data structures; however, I can also see the counterargument in exploratory data analysis environments.
Context is everything.
pyjanitor, mentioned above, uses pandas_flavor's direct method registration vice the builtin pandas custom
Application Programming Interface (API).
accessor extension API.
Custom data types
This is absolutely another extension mechanism I can see having a need for in the future that I did not know about
before diving into this topic for the package and blog post. However, I didn't want to create a contrived one just
for the blog post because there are other good, useful open-source Python packages that do this. The documentation
e.g., cyberpandas17 for custom data types related to IP Addresses.
on this topic is pretty good and the ecosystem page has examples. I also recommend watching
this dated but still relevant talk by core developer Will Ayd on the topic.
Subclassing existing pandas data structures
This is a much more time-consuming endeavor you'll need a good reason to pursue. To some degree, with custom accessors,
this may be rarely needed in new code relegated mostly to the trash heap of legacy. Not a ton of good reasons come to
But, again, I can't think of a good reason why you'd need to do that either.
mind but if you ever needed to override a pandas data structure method that might be one. A good example here that
I've used extensively is geopandas18.
Third-party plotting backends
Very cool that this is supported but also incredibly niche. I can't imagine even most advanced users and developers of
pandas and related packages will ever need to use this. However, they may well benefit from it when a new plotting
package developer can take advantage of it.
Creating a Python package from scratch is annoying. There is no standard library tooling to help. There is no
authoritative take on folder structure. So sling something into a single file script or Jupyter notebook to
languish within Untitled7.ipynb to avoid the hassle. This did the job it needed to. Then it needs to be shared and
reused ...
All of this can be just enough friction to delay starting on a new idea. At least that has been the case for me.
Let's even say a particularly motivated mood strikes. Putting together the project structure will be error-prone and
require more effort searching the internet for arcane setup.cfg incantations than writing the actual code for the
idea. Maybe that's all you have time to get done before it's off to other activities.
Or worse: you don't even get that far.
Not a great use of time. This should be the easy part!
As a result of going through the process of spinning up a few new projects recently I
decided to take the time to better understand the Python packaging ecosystem and create a project boilerplate
template as an improvement over copying a directory tree and doing find and replace.
Why?
seems particularly popular.
Is this reinventing the wheel? A valid question. Certainly somebody has already done this drudgery you say. And you'd be
right. A quick web search will turn up pages of project templates. Same with github
and pypi. So the question remains. There are some good reasons in this case, some reasons I did not
reach for something already available.
First, I had been reading a book that went into detail on the
is excellent and highly recommended (DISCLAIMER: I took this opportunity to look into affiliate marketing through
Amazon so the link above is one; if you care, it's easy enough to do an internet search on "serious python" and bypass).
topic and felt like applying what I was learning: this is always a good reason.
Second,
this is the type of task a Python expert certainly should be comfortable executing; somewhat ironically, it'll also
often be a task that is already taken care of at a company or on a project unless you're involved at a very early
stage.
Third, I can't find the quote to do proper attribution unfortunately, but I recall
reading something I'll paraphrase that resonated with me
Don't use anything you can't take the time to learn well.
Whether it's a 4,000+ line .vimrc file or a project template like this a time will almost certainly come when you need
to change something. That's when the inevitable technical debt comes due and pay you will. My experience has been that
adding just what you need (and understand) and iterating over time is always a better strategy.
Definitely not another case of ... Lastly, as I became more engrossed in the details of the endeavor, the point became to
be more opinionated especially with respect to dependent packages. I wanted something a coworker, colleague,
collaborator, etc., could use immediately with my recommended dependencies for various different types of tasks. Turns
out this is straight forward to bake in.
Familiarity in the sense that I had used someone else's cookiecutter template before.
There are many possible approaches but the one I had already some familiarity with in the Python ecosystem was
cookiecutter. From their messaging cookiecutter is
A command-line utility that creates projects from cookiecutters (project templates), e.g. creating a Python package
project from a Python package project template.
Using a cookiecutter someone else has created is trivial as detailed in the
documentation
cookiecutter gh:bpw1621/ordained is shorthand for accessing a github hosted
cookiecutter template.
cookiecutter https://github.com/bpw1621/ordained
or
cookiecutter ordained
when the template has been pulled down already. Typically, you are greeted with a few questions to configure details
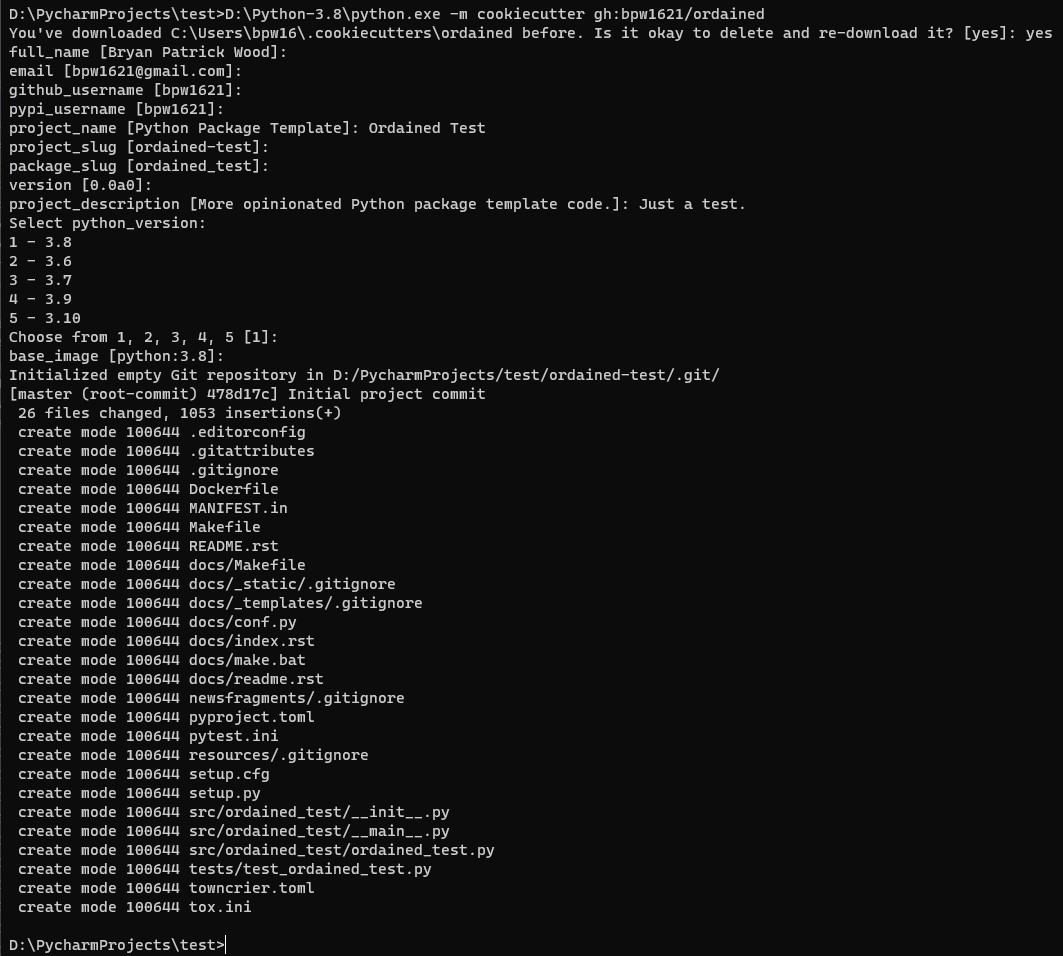
about the project template instantiation and then off to the races. For instance, the ordained cookiecutter template
prompts as follows
I only needed to specify two options: the project name and description.
Anyone other than me would have to enter all of their personal information but that can be handled with cookiecutter's
support for user config.
The defaults attempt to be sane and minimize redundant data entry. At this point a fully functional Python package has
been created and the initial boilerplate version controlled in git. Since the options for specifying the type of
virtual environment one wants at this point are a little complex that next step is left out of the automation (at least
at the moment, viz., below).
Not sure the Python community has coalesced around cookiecutter as the solution, but
it's at least a cut above copying an existing project and editing the various parts. Having used tools in other
And they have been improving, viz.,
here.
programming languages (e.g., Yeoman in Javascript) there is room for improvement. That said, one
of my favorite quotes is
The perfect is the enemy of the good.
Le mieux est l'ennemi du bien.
Since the virtual environment creation is not automated a good default choice, after creating and activating the
project's virtual environment, is pip install -e .[base,dev,doc,test]. This will pull in those dependencies I
typically do not want to live without as a matter of quality of life (i.e., base), those integral for
development (i.e., dev), those needed to generate documentation (i.e., doc), and those needed to test (i.e., test).
Including any of the other requirements groups will depend on what the project is trying to accomplish.
So What?
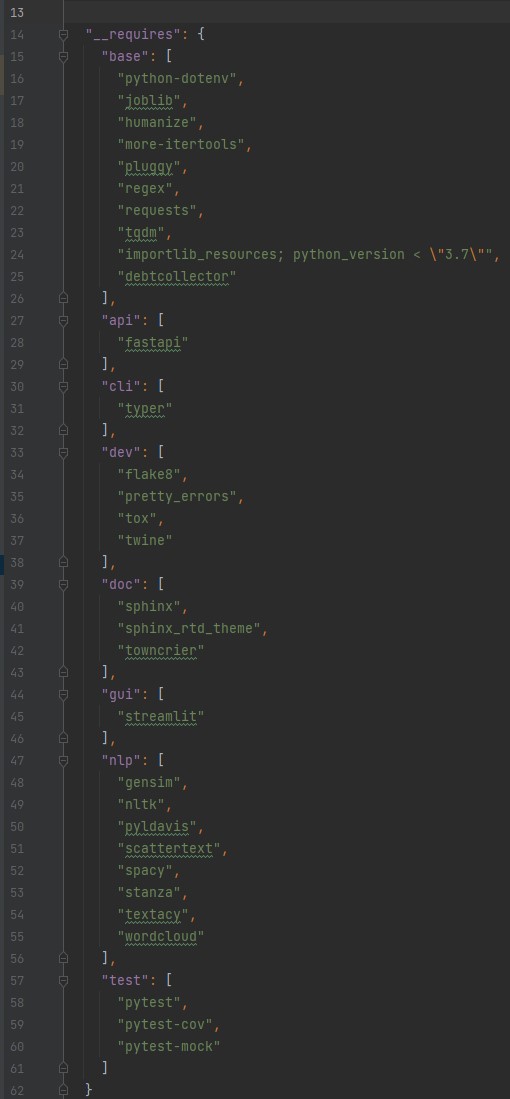
A large part of the opinionated aspect resides in the specification of recommended project dependencies. This is accomplished
using setuptools support for options.extras_require to provide groups of dependencies to pull in covering different
topics. Those groups are specified in a requirements group dictionary as part of the cookiecutter JSON configuration.
Here's the snippet from cookiecutter.json
Configuration keys in cookiecutter with two leading underscores stay part of the context but
are suppressed from the initial configuration options provided to the user. This is unfortunately still an unreleased
feature (as of cookiecutter 1.7.3) so using ordained requires installing
cookiecutter from the HEAD of master (pre-release version
of 2.0.0 as of this writing).
These topic based recommendations are very much a work in progress. It is largely informed, at the moment, by what I
have been working on most recently and there are clearly large gaps. A hope is that as folks use this that it will be
a wellspring of suggestions as to the Python packages I am not even aware that should be included as well as better
alternatives to those I have grown to rely on. I will put aside why I made these choices for a future post after the
recommendations are a little more fully fleshed out. At any rate, if you have your own dependency package
recommendations it is trivial to fork the project and change a single JSON object in the top-level cookiecutter.json
with them.
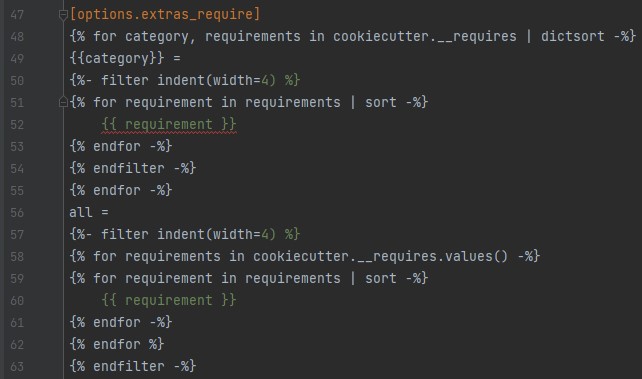
The requirements group dictionary is used in a Jinja2 template to generate setup.cfg
in the project
There is some unseemly vanity in sharing some of these gory technical details just because
I think they're clever. That said, it did take me sometime (viz., the - all over the place) to get it quite
right given I had never written a complex Jinja2 template like this before.
This could have been jammed inline in the project template, but I think it is cleaner to leave
it here and less digging through the guts of the template to make additions and modifications.
which creates the requirements groups lexicographically sorted with a special all group for the kitchen sink.
Here are some other capability highlights provided directly out of the box
I'll be dogfooding this, but I would love feedback
if anyone else decides to give it a spin. Drop me a comment on the blog or the project.
Github pull requests welcome.